2025 10 26 左永安 顧問/講師/委員/宮主/秘書長/永續長/執行長/理事長 經濟部 iPAS AI應用規劃師初級能力鑑定 人工智慧基礎概論 (L11) 機器學習(Machine Learning)是一種透過 數據訓練 模型,使 機器 具備 預測 與 分類 能力的技術, 常應用於 文字辨識、語音辨識、圖像辨識 等領域。機器學習的 步驟包含: (1)準備訓練資料:(2)訓練模型:(3)測試及評估模型:
機器學習(Machine Learning)
是一種透過 數據訓練 模型,使 機器 具備 預測 與 分類 能力的技術,
常應用於 文字辨識、語音辨識、圖像辨識 等領域。
一般而言,資料量愈大 且經過 完整的資料處理,
模型的效果通常會更好。
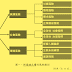
簡述 機器學習的 步驟包含:
(1)準備訓練資料:
包含資料的蒐集、過濾雜訊 及前處理;
(2)訓練模型:
將前項 準備好 的 訓練資料 輸入 演算法中,並 適度調整 參數,
使模型儘量符合資料之模式或分佈;
(3)測試及評估模型:
測試 並 評估 該 模型的效能,並反覆訓練之;經多次調校仍不佳時,
或許選用其他模型 再重覆前 述流程。
依訓練方式,有以下幾種學習方法:
(1)監督式學習(Supervised learning)
監督式學習主要應用於 分類(Classification)與 迴歸(Regression)
任務,透 過 帶有標記(Labeled Data)的訓練數據來訓練模型,
使其學習 輸入特徵 與 對應標 記 之間的關聯性。
在訓練過程中,模型不斷調整內部參數,以提高對未知數據的 預測準確度,
從而 實現 對 未見 數據的 有效分類 或 數值 預測。
分類模型目標為「如 何將輸入數據 分配至 不同類別」,
例如 垃圾郵件過濾(辨別郵件是否為垃圾郵件)、
影像識別(辨識圖片中的物件類別)。
迴歸模型目標為「學習 輸入變數 與 連續數值 之間的映射關係」,
例如 房價預測(根據房屋特徵預測價格)、
銷售額預測(根據 市場數據預測未來銷售)。
(2)非監督式學習(Unsupervised Learning)
不同於監督式學習,無需使用事先標記好的訓練數據。
演算法會自動從 未標 記的數據 中 發掘潛在的模式、結構或
分群(Clustering),進而揭示 數據內部的關聯 性和特徵。
非監督式學習常用於
資料探索、特徵提取 和數據降維 等任務,
廣泛應 用於
市場區隔分析、異常偵測、推薦系統 和 影像壓縮 等領域。
(3)強化學習(Reinforcement Learning, RL)
強化學習不同於監督式學習和非監督式學習,
是一種 基於「回饋(反饋)機 制」的 學習方法,
透過 評分機制 與 獎勵措施 的制定,讓人工智慧進行自我評估
並朝 獲取最大獎勵的方向進行學習。
強化學習的核心在於 讓代理(Agent)透過與環 境 的互動,
學習如何選擇 最佳行動策略,以獲得最大的累積回報。
強化學習特別 適合用於
需要「試錯學習(Trial-and-Error)」和「長期規劃」
的任務,
例如 遊戲 AI、 機器人控制 和 自動駕駛等領域。